目次
はじめに
こんにちは。fusassyです。最近Xのタイムラインで流れてきた並べ替えアルゴリズムの可視化について、非常に面白いなと思って見ていました。可視化された動画のみならず、利用されている並べ替えアルゴリズムの解説も備忘録として残しておきます。
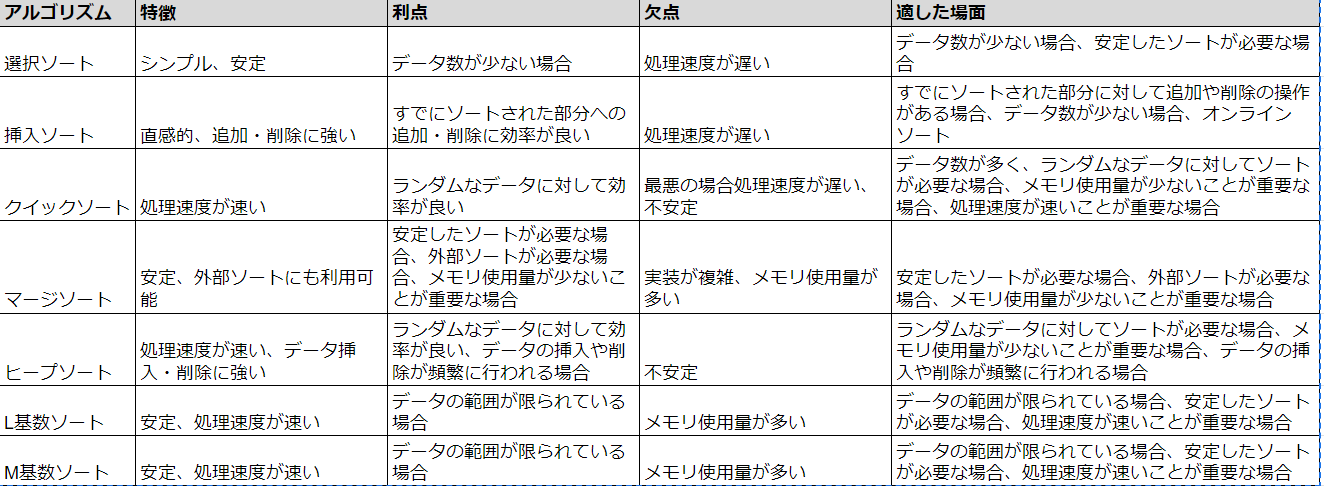
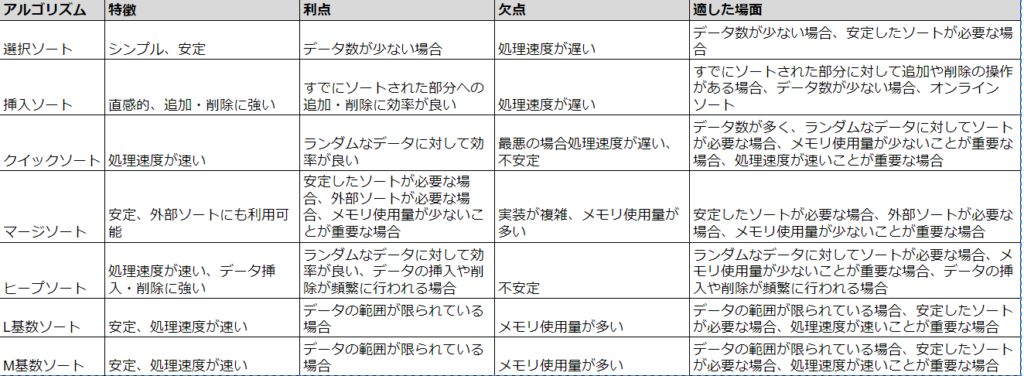
下記のアルゴリズムについて、処理速度やメモリ使用量、データの種類によって適したものを選択します。
1:選択ソート
2:挿入ソート
3:クイックソート
4:マージソート
5:ヒープソート
6:L(最小)SD基数ソート
7:M(最大)SD基数ソート
各種アルゴリズムの開設について
1. 選択ソート
イメージ: クラスで一番背の高い人を探す
- 生徒を一人ずつ背の順に並ばせる
- 一番背の高い人をクラスの後ろに移動
- 残りの中から一番背の高い人を探し、後ろに移動
- これを繰り返すまで、全員が背の順に並ぶ
特徴:
- 比較操作と交換操作がシンプルで分かりやすい
- 安定したソートである(元の順序が保持される)
- データ数が少ない場合に効率が良い
- ランダムなデータに対しては平均的な処理速度
欠点:
- 全ての要素を比較するため、処理速度が遅い(O(n^2))
- 書き込み操作が多いため、メモリ使用量が多い
適した場面:
- データ数が少ない場合
- 安定したソートが必要な場合
- 比較と交換の操作がシンプルなアルゴリズムを学習したい場合
2. 挿入ソート
イメージ: 積み木をソートする
- 最初の積み木を正しい位置に置く
- 次の積み木を、すでに並んだ積み木の中に適切な位置に挿入していく
特徴:
- 直感的なイメージがしやすい
- 比較操作と移動操作が比較的少ない
- すでにソートされた部分に対して追加や削除の操作がある場合に効率が良い
欠点:
- 挿入位置を見つけるために、過去の積み木をずらす必要があるため、処理速度が遅い(O(n^2))
- すでにソートされているデータに対しては、選択ソートよりも非効率
適した場面:
- すでにソートされた部分に対して追加や削除の操作がある場合
- データ数が少ない場合
- オンラインソート(データが逐次的に流れてくる場合)
3. クイックソート
イメージ: じゃんけんを使って兵士を左右に分ける
- ランダムに一人をピボット(基準点)として選ぶ
- ピボットより大きい兵士は右へ、小さい兵士は左へ移動させる
- 左右のグループを再帰的に同じようにソートする
- すべての兵士が適切な位置に並ぶまで繰り返す
特徴:
- 平均的な処理速度が速い(O(n log n))
- 空間複雑度が低い(O(log n))
- ランダムなデータに対して効率が良い
欠点:
- 最悪の場合、処理速度が遅くなる(O(n^2))
- ピボットの選び方によって処理速度が大きく左右される
- 不安定なソートである(元の順序が保持されないことがある)
適した場面:
- データ数が多く、ランダムなデータに対してソートが必要な場合
- メモリ使用量が少ないことが重要な場合
- 処理速度が速いことが重要な場合
4. マージソート
イメージ: 二つの書類を合体させる
- データを半分に分割する
- それぞれのデータを再帰的にソートする
- 二つのソート済みデータをマージ(結合)する
特徴:
- 安定したソートである
- 最悪の場合でも処理速度が遅い(O(n log n))
- 空間複雑度がO(n)
- 外部ソートにも利用できる
欠点:
- 他のソートアルゴリズムよりも実装が複雑
- 再帰処理を使用するため、メモリ使用量が多い
適した場面:
- 安定したソートが必要な場合
- 外部ソートが必要な場合
- メモリ使用量が少ないことが重要な場合
5. ヒープソート
特徴:
- 平均的な処理速度が速い(O(n log n))
- 空間複雑度が低い(O(1))
- ランダムなデータに対して効率が良い
- データの挿入や削除にも効率が良い
欠点:
- ヒープ構造の構築と修復に計算コストがかかる
- 不安定なソートである
適した場面:
- データの挿入や削除が頻繁に行われる場合
- ランダムなデータに対してソートが必要な場合
- メモリ使用量が少ないことが重要な場合
6. L(最小)SD基数ソート
イメージ: バケツを使って貝殻を分別する
- データの範囲を等間隔に区切ったバケツを用意する
- 各データをバケツに入れる
- バケツの中のデータを順番に取り出し、正しい位置に並べる
特徴:
- 安定したソートである
- 処理速度が速い(O(n + k))
- データの範囲が限られている場合に効率が良い
欠点:
- バケツの数が必要なため、メモリ使用量が多い
- データの範囲が広い場合に非効率
適した場面:
- データの範囲が限られている場合
- 安定したソートが必要な場合
- 処理速度が速いことが重要な場合
7. M(最大)SD基数ソート
イメージ: L基数ソートと同様に、バケツを使ってデータを分別するが、最大値ではなく最大範囲のバケツから取り出す
特徴:
- L基数ソートとほぼ同じ
欠点:
- L基数ソートとほぼ同じ
適した場面:
- L基数ソートと同じ